051.2 Lesson 1
Certificate: |
Open Source Essentials |
|---|---|
Version: |
1.0 |
Topic: |
051 Software Fundamentals |
Objective: |
051.2 Software Architecture |
Lesson: |
1 of 1 |
Introduction
The internet is ubiquitous in our modern world, as are mobile and web-based applications. These tools are used seamlessly by a large portion of the world’s population and power everything from instant messaging to more complex activities like purchasing mining equipment for large companies.
Behind all these seemingly simple interfaces and online services is an architecture — an arrangement of cooperating pieces of software — that we often take for granted. You need to know a bit about this architecture to understand how all the pieces of the internet fit together and how software can deliver real value to its users.
In this lesson, we will look at some of the software architectures behind web applications, which are server-based software systems, and how they are used within systems that almost everyone is familiar with.
Servers and Clients
When you use online systems, it is highly likely that at some point you have encountered a message like the one in Sample screen shown while a response is underway.
Let’s step back a little bit and look at the context in which you’re seeing this message. Say you are trying to gain access to your banking account through your bank website. When you try to get onto the banking website on your laptop, you use a type of software (i.e., application) called a web browser, such as Google Chrome or Firefox. In this case, the browser on your computer sends a request to another computer hosting the website. This particular kind of computer is called a server. It is specially designed to run 24/7, always serving new requests coming in from all parts of the world.
So a server is a computer, just like the one you use to work with, play video games, and do programming assignments. However, there is one main difference: A server normally uses all its resources for the software application running on it. In this example, the software is a web application, a computer program that runs on the server.
In Sample screen shown while a response is underway, the server has received a request from a browser, and the application running on the server is processing the resulting operation. This operating could be querying a database to fetch a user’s details in the bank, or communicating with another server to verify a special discount on the user’s next loan.
In this example, we call the browser running on your machine the client application, or simply put, the client. The client interacts with the remote server.
The network communication between client and server might take place inside an enterprise network, or across the worldwide network we call the internet. A common characteristic of client-server interaction is that a server can establish multiple relationships with multiple clients. Think about the previous example: the website of a bank hosted on a server can attend thousands of requests per minute from multiple locations, each with a user trying to access their personal bank account.
Not all scenarios are structured like a browser interacting with a server that does almost all the processing. In some cases, the client can be the primary instance for processing; this concept is called a fat client (or thick client), where the client stores and processes the majority of the tasks instead of relying on the server’s resources. In our banking example, in contrast, the browser is a thin client that relies on the server to compute and return information through the network.
An example of a fat client is a video game desktop application, where the bulk of the data storage and processing is done locally, using the computer’s GPU, RAM, CPU, and disk space to process the information. Such an application rarely relies on an external server, especially if the game is being played offline.
Both approaches have pros and cons: For a thick client, network instability is less of an issue compared with a thin client that relies on a remote server, but software updates can be harder to apply and the fat client requires more computer resources. For a thin client, the lower costs could be a great advantage. For either kind of client, providing personal data to a third-party application can be an issue.
Web Applications
A web application is software that runs on a server, processes user interactions, and is contacted by either fat or thin clients through a computer network. Not all websites are considered web applications: Simple static web pages without interactivity are not considered web applications because the server doesn’t run an application to process actions requested by the client.
A lot of web applications can be divided into two groups: the single page application (SPA) and the multi-page application (MPA). An SPA has only one web page, where all data exchange and loading occur without the need for redirecting the user to another web page inside the application. An MPA, in contrast with the SPA, has multiple web pages. A data change might either refresh the same web page that originated the action or redirect the user to another web page.
Consider the previous example, where a user wants to check their most recent account transactions on the internet banking website. Imagine that a transaction happens after the web page is loaded. If the bank web application is an SPA, the new transaction will be displayed automatically on the same web page, without redirecting the user to a new page. If the user checks their loans, the new information is also displayed on the same page, avoiding the need to redirect the user to a new web page. Altering the page without redirecting the user makes the navigation smooth.
For an MPA, when the user requests the loan web page, the server must redirect the user to a new location, which means another web page.
A famous example of an SPA web application is Google Mail (Gmail). It doesn’t redirect the user to completely new page when, for example, the user wants to display the the spam folder; the application merely refreshes the specific part of the display that shows all spam messages, and stays on the same web page.
On the other hand, a famous MPA application is Amazon.com, the ecommerce giant, where each item is located on a distinct web page.
One advantage of an MPA over an SPA is that web analytics are much easier to gather and measure. This is crucial to help the developers optimize internet search results.
Usually, a web application is divided into two separate parts: frontend and backend. The frontend is the view layer, where the user interacts with a browser using the page elements by clicking, selecting, or typing. This is where the data from the server is received, formatted, and displayed to the user through the browser.
The backend is generally the larger part of a web application. It comprises the business logic, communication handlers, the majority of the data processing, and the data storage. Data storage employs a separate database management system connected to the backend.
The frontend and backend communicate with each other. Data requests are forwarded by the frontend to the backend, and the data returned by the backend is received, formatted, and displayed by the frontend to the user.
In our simple example of fetching the latest transaction in a user’s bank account, the action is interpreted by the frontend of the application, which is running in the browser on the user’s desktop. This request is then sent through the internet to the backend of the application, which validates whether the user is allowed to perform the action, fetches the data, and returns the list of transactions back to the frontend loaded in the browser. The browser then formats and displays the data to the user.
Application Programming Interface (API)
No software is useful without communicating with internal and external components. So how can the client communicate with the web application? How can the frontend send data to the backend?
Software applications communicate with each other via an application programming interface (API), running over basic internet communication protocols. Protocols are standards and rules developed to ensure that two or more applications exchange commands and data.
The main benefit of an API is to decouple different parts of application while allowing them to cooperate in processing data. APIs also centralize the data flow in pre-defined channels, acting like a gateway that ensures that everyone uses the same way for coming and going. In web applications, APIs are vital for the application’s functionality, as they allow user interaction, the delivery of processed information, requests for data storage, and many other tasks. An API can be used by the client to request actions that will be executed on the server, for example.
Let’s go back to the banking web application example. To log into an account through a web application, the user generally types data such as username and password into certain text fields and clicks a “Login” button. The browser grabs this information and calls a backend API. The web application running on the remote server receives the user data, validates the user, verifies the right of the user to gain access, and finally sends a response back to the browser. In order for the user to communicate with the server, it is mandatory for both client and server to send data back and forth. That is what APIs enable.
Notice that the bank’s web application does not expose other sensitive information; it shows the user only the fields that are allowed and necessary for a desired interaction. The rest is hidden from the user.
Communication between APIs can be based on very different designs and protocols. The hypertext transfer protocol (HTTP) is by far the most frequently used protocol in web applications. Hypertext is text with links to other texts, the concept underlying the links in HTML web pages. Hyperlinks thus form the basis for constructing web pages and displaying them in browsers.
HTTP was designed for client-server applications, where the resources are requested from a server and then returned to the client over the network using a predefined structure specified by the HTTP protocol.
For a structured web application, software engineers design the application with separate parts or modules. This separation of responsibility allows clearly defined tasks and responsibilities, leading to faster development and better maintenance.
Let’s take, as an example, an application with two internal modules: one that implements the business logic, and the other relying on a third-party integration. This third party is an external company that provides its API for some specific purpose — weather forecasting, say. If the weather server is down, it is impossible to get weather details, and if this data is crucial to the final processed output, the user might experience some temporary headaches if there is no alternative source for the data.
Now imagine that this third-party provider is replaced and the new one has a different way of handling the same API. The separation of modules means that developers of only one module have to update it. The business logic in the other module doesn’t have to be touched at all, or at least calls for minimal updates.
The need for clear process structures also influences the design of the APIs in order to make them easier to use. The representational state transfer (REST) concept is an architectural style with a set of guidelines for designing and implementing access to data in an application.
There are six REST principles. For the sake of simplicity, we are going to explain three that are most relevant to this lesson:
- Client-server decoupling
-
The client should know only the resource URI, through which communication with the server occurs. This principle allows greater flexibility. For example, when the backend side of the application is refactored, or there is a major architectural change to a backend database, the frontend does not need to be updated in conjunction. It simply continues to send the same HTTP requests to the backend.
- Statelessness
-
Each new request is independent from the previous ones. It is no coincidence that the HTTP protocol is widely used for applications that follow REST principles, since HTTP has no knowledge of previous HTTP requests; for each new request, all the necessary information must be sent in order to correctly process the request. For example, a web application that implements this principle has no knowledge whether the client is logged in (authenticated). So for each HTTP request, the client must send an authentication token. The server can use this token to verify whether the request should be blocked or processed.
One of the main advantages of this principle is easier scaling, because the server can process millions of requests without checking user details.
- Layered architecture
-
The application is composed of multiple layers, and each layer can have its own logic and purpose, such as security or data acquisition. The client may never know how many layers exists, or whether they are communicating directly with a specific layer inside the application.
APIs following the REST principles are called RESTful, and in the modern web, the REST design is followed by many web applications. Although a RESTful API does not need to implement these principles using the HTTP protocol, it is almost universally used in the REST model given its robustness, simplicity, and ubiquitousness in the world wide web environment.
Architecture Types
Dozens of architectural styles and standards exist that attempt to organize the structures of web applications, Like almost everything in the computer world, there is no “winner,” only a set of pros and cons for each model. An important paradigm is the so-called microservice architecture, that was created as an alternative to the older monolithic architecture.
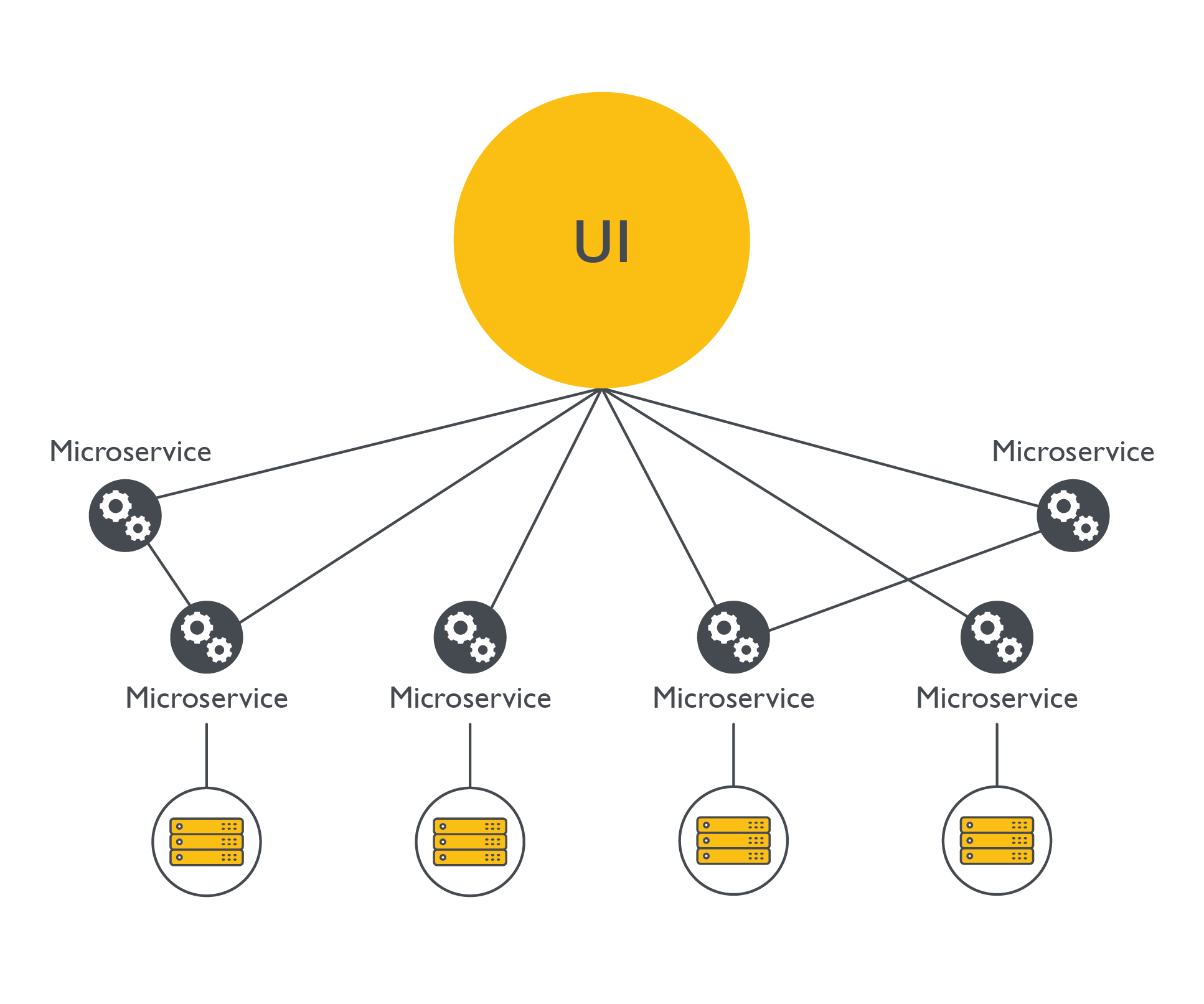
The microservice architecture is a software model composed of multiple interdependent services that together form the final application. This architecture aims to decentralize the codebase: Multiple layers of software are split into multiple smaller applications for better maintenance (Microservice architecture).
In contrast, a monolithic architecture contains all services and resources of the application in one application (Monolithic architecture).
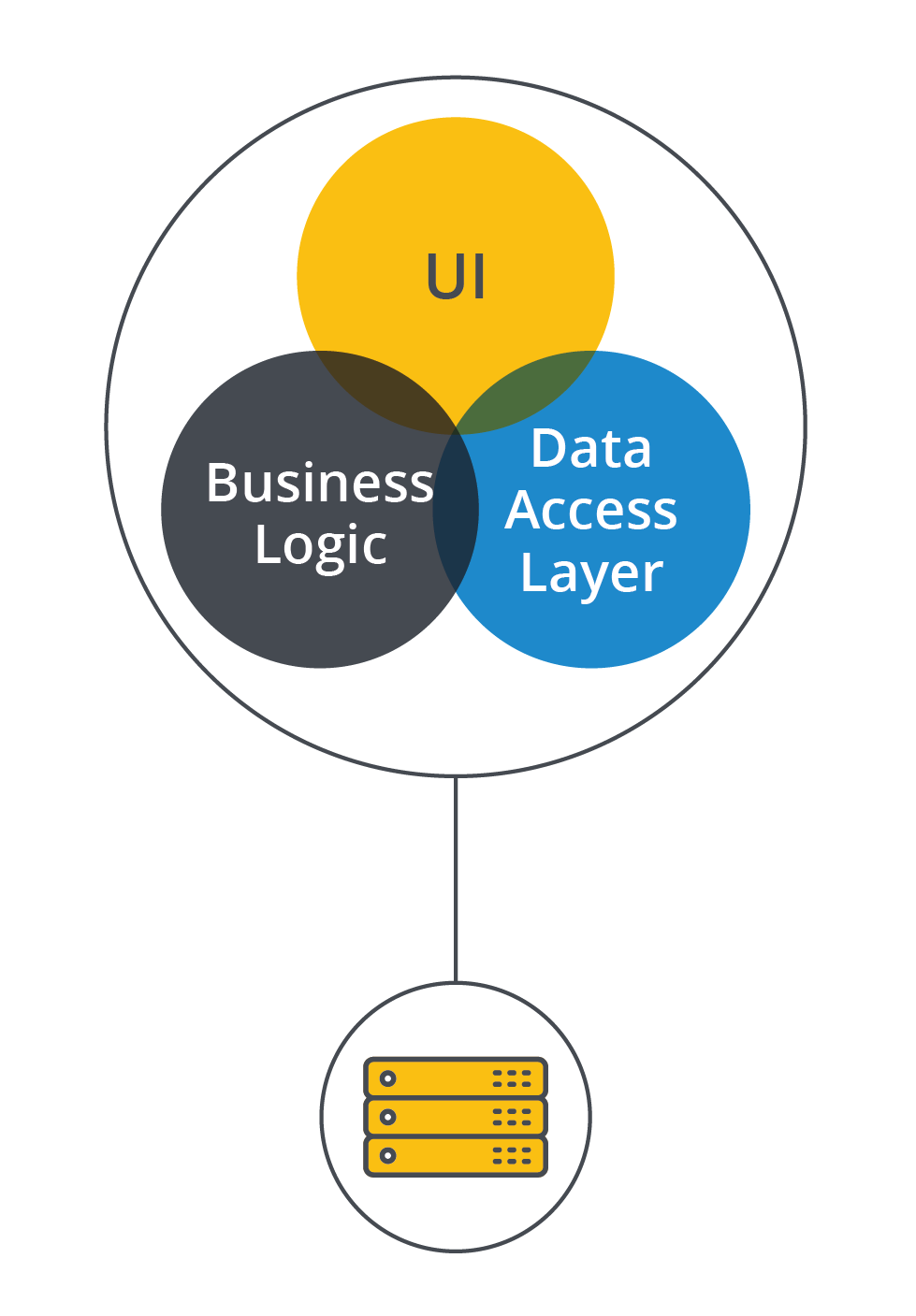
The images show that the microservice model is decentralized and the application relies on multiple services, each with its own database, codebase, and even server resources. As the name implies, each microservice should be smaller than its monolithic counterpart, which takes responsibility for all services.
The monolithic application encapsulates all its resources into one single unit. All the business logic, data, and codebase are centralized in one huge block, which is why it’s called a “monolith.”
Users hardly notice whether a web application is running as a monolithic or microservice model; the choice should be transparent. Our banking application, for example, could be a monolith where all the business logic regarding payments, transactions, loans, etc. is located in the same codebase running on one or more servers. On the other hand, if the banking appliction uses a microservice style, it probably has a microservice dedicated to processing payments and another microservice just for issuing loans. The latter microservice calls yet another microservice to analyze the probability that the applicant will default on the payment. The application could have thousands of smaller services.
The monolithic approach requires more maintenance overhead when the application grows larger, especially with multiple teams coding in the same codebase. Given the centralized software resources, it is highly likely for one team to change something that breaks the another team’s part of the application. This could be a real headache for larger teams, especially when there is a great number of teams.
Microservices are much more flexible in that regard, because each service is managed by only one team. One team can, of course, manage more than one service. The code changes are easily done and competing resources are not a real issue. Since each service is interconnected, any point of failure could have a negative impact on the entire application. Furthermore, since there are multiple database instances, servers, and external APIs communicating with each other, the resilience of the whole application is only as good as its weakest microservice.
One advantage of the monolithic approach is having one centralized data source, which makes it easier to avoid data duplication. The approach also reduces the consumption of cloud resources, because one larger server needs fewer computer resources than multiple decentralized servers. A microservice application of roughly the same size puts a greater burden on the cloud.
Guided Exercises
-
What are the main differences between a fat and a thin client?
-
Is it correct to assume that every website is a web application?
-
What is the REST model?
-
What is the preferred model for developing large and modern web applications with multiple development teams? Why?
-
What is the most commonly used protocol to exchange data between web applications?
-
Name two disadvantages of multi-page applications compared to single-page applications.
-
Describe one advantage of a monolithic system over a microservice system, and one advantage the microservice system has compared to a monolithic one.
Explorational Exercises
-
In 2021 the NASA Perseverance Rover landed on Mars, with one of its goals to determine whether life ever existed on Mars. Although the Rover could be controlled by distance here on Earth, it also can control itself in most situations. Why is it a good idea to project a rover like that as a fat client?
-
Consider a modern, self-driving, personal car that connects to an external server to exchange data. Should it be a fat or a thin client?
Summary
This lesson explained the core concepts of software architecture for web applications. The lesson explained how they are commonly structured and organized, and the main differences between the monolithic and microservice models. We covered the concepts of servers and clients, and the basics of web application communication between clients and other software programs.
Answers to Guided Exercises
-
What are the main differences between a fat and a thin client?
A fat client does not require a constant connection to a remote server that gives back critical information to the running client. The thin client relies heavily on the information processed by an external source. Another difference is that a fat client is responsible for the bulk of the data processing, thus requiring more computing resources than its thin counterpart.
-
Is it correct to assume that every website is a web application?
No. There are websites that are not software applications. A web application interacts with the user, who might input data and use web functionalities in real time. Simple websites such as an advertisement for a social event, which functions like a web banner, are not web applications. These non-interactive web sites are easier to maintain and require tiny computing resources to host and deliver the web pages. A web application requires much more computing resources, more robust servers, and functionalities that handle users, such as restricted access and permanent data storage.
-
What is the REST model?
The REST model is a software architecture model providing applications with a development guide for better usability, clarity, and maintainability. One of the principles outlined in the set of REST guidelines is the layered architecture, used primarily for cohesion and to lower the dependency of the various APIs' internal components.
-
What is the preferred model for developing large and modern web applications with multiple development teams? Why?
The microservice software model provides a flexible framework in which teams collaborate on the same software application, providing easier concurrency for two or more teams maintaining a large web application. Because the framework is decentralized, each team can update a specific business domain without having to update other components.
-
What is the most commonly used protocol to exchange data between web applications?
HTTP is the most used protocol for exchanging data and commands between servers and clients.
-
Name two disadvantages of multi-page applications compared to single-page applications.
A multi-page application reloads all the elements in the web page when the user triggers some actions, instead of updating only the changed elements. Performance suffers from this design. Another disadvantage of an MPA is clunkier user interactivity, where each page load creates a loss in user friendliness. In contrast, the visual effect could be continuous in an SPA.
-
Describe one advantage of a monolithic system over a microservice system, and one advantage the microservice system has compared to a monolithic one.
A monolithic system can make data administration easier because the data is located in one big database, instead of being scattered in multiple databases. A microservice application, on the other hand, can improve code development and maintenance; multiple teams can work on different business logic without blocking the progress of other teams.
Answers to Explorational Exercises
-
In 2021, the NASA Perseverance Rover landed on Mars. One of its goals was to determine whether life ever existed on Mars. Although the Rover can be controlled over a long distance by an application on Earth, it also can control itself in most situations. Why is it a good idea to design a rover like that as a fat client?
The time a communication signal takes to be sent from Earth and received on Mars can vary depending on the positions of those planets, but it can take up to twenty minutes. Thus, command and control of a distant rover in motion is impossible, especially taking unexpected situations into account. Ideally, the rover should command itself in most situations. That is achieved using artificial intelligence (AI) training (machine learning), so that the rover becomes more independent from manual commands. To make that possible and to rely less on distant signals, the rover was projected to have its own resources and the majority of the computing processes ran locally, matching the definition of a fat client.
-
Consider a modern, self-driving, personal car that connects to an external server to exchange data. Should it be a fat or a thin client?
An autonomous vehicle could delegate the heavy data processing to an external and reliable server, but this would be susceptible to offline periods when critical data processing is required. Therefore, it is imperative for the autonomous vehicle to process the majority of tasks — and this requires it to be a fat client with multiple redundancy.