051.2 Lektion 1
Zertifikat: |
Open Source Essentials |
|---|---|
Version: |
1.0 |
Thema: |
051 Software-Grundlagen |
Lernziel: |
051.2 Softwarearchitektur |
Lektion: |
1 von 1 |
Einführung
Das Internet ist in unserer modernen Welt allgegenwärtig, ebenso wie mobile und webbasierte Anwendungen. Diese Tools werden von einem großen Teil der Weltbevölkerung genutzt und machen Sofortnachrichten ebenso möglich wie den Online-Kauf von Bergbauausrüstung für große Unternehmen.
Hinter all diesen scheinbar einfachen Schnittstellen und Online-Diensten verbirgt sich eine Architektur — eine Struktur von zusammenarbeitenden Softwareteilen — die wir oft als selbstverständlich ansehen. Man muss ein wenig über diese Architektur wissen, um zu verstehen, wie all die Teile des Internets zusammenpassen und wie Software ihren Nutzern einen echten Mehrwert bietet.
In dieser Lektion werden wir uns einige Softwarearchitekturen hinter Webanwendungen ansehen, die serverbasierte Softwaresysteme sind, und wie sie in Systemen eingesetzt werden, die fast jeder kennt.
Server und Clients
Wenn Sie Online-Systeme nutzen, ist es sehr wahrscheinlich, dass Sie irgendwann auf eine Meldung wie die in Beispiel für eine Anzeige, während eine Antwort unterwegs ist gestoßen sind.
Treten wir einen Schitt zurück und betrachten wir den Kontext, in dem diese Meldung erscheint. Nehmen wir an, Sie versuchen, über die Website Ihrer Bank Zugang zu Ihrem Bankkonto zu erhalten. Wenn Sie von Ihrem Laptop auf die Website der Bank zugreifen, verwenden Sie eine Software (d.h. eine Anwendung), die als Webbrowser bezeichnet wird, z.B. Google Chrome oder Firefox. In diesem Fall sendet der Browser auf Ihrem Computer eine Anfrage an einen anderen Computer, der die Website hostet. Diese Art von Computer wird als Server bezeichnet. Er ist speziell dafür ausgelegt, rund um die Uhr zu laufen und ständig neue Anfragen zu bedienen, die aus allen Teilen der Welt eingehen.
Ein Server ist also ein Computer, genau wie der, mit dem Sie arbeiten, Videospiele spielen und Programmieraufgaben erledigen. Es gibt jedoch einen wesentlichen Unterschied: Ein Server verwendet normalerweise all seine Ressourcen für die Softwareanwendung, die auf ihm läuft. In diesem Beispiel ist die Software eine Webanwendung.
In Beispiel für eine Anzeige, während eine Antwort unterwegs ist hat der Server eine Anfrage von einem Browser erhalten, und die auf dem Server laufende Anwendung verarbeitet die daraus resultierende Operation. Diese Operation könnte eine Datenbankabfrage sein, um die Daten eines Benutzers in der Bank abzurufen, oder die Kommunikation mit einem anderen Server, um einen Sonderrabatt für den nächsten Kredit des Benutzers zu überprüfen.
In diesem Beispiel bezeichnen wir den Browser, der auf Ihrem Rechner läuft, als Client-Anwendung, oder, einfach ausgedrückt, als Client. Der Client interagiert mit dem entfernten Server.
Die Netzwerkkommunikation zwischen Client und Server kann innerhalb eines Unternehmensnetzwerks oder über das weltweite Netzwerk, das wir als Internet bezeichnen, stattfinden. Ein Merkmal der Client-Server-Interaktion ist, dass ein Server mehrere Verbindungen zu mehreren Clients aufbauen kann. Denken Sie an das vorherige Beispiel: Die Website einer Bank, die auf einem Server gehostet wird, kann Tausende von Anfragen pro Minute von mehreren Standorten erhalten, wobei jeder Benutzer versucht, auf sein persönliches Bankkonto zuzugreifen.
Nicht alle Szenarien sind so strukturiert, dass ein Browser mit einem Server interagiert, der fast die gesamte Verarbeitung übernimmt. In einigen Fällen kann der Client die primäre Instanz für die Verarbeitung sein; dieses Konzept wird als Fat Client (oder Thick Client) bezeichnet, bei dem der Client den Großteil der Aufgaben speichert und verarbeitet, anstatt sich auf die Ressourcen des Servers zu verlassen. In unserem Bankbeispiel ist der Browser dagegen ein Thin Client, der sich auf den Server verlässt, um Informationen zu berechnen und über das Netzwerk zurückzugeben.
Ein Beispiel für einen Fat Client ist die Desktop-Anwendung eines Videospiels, bei der der Großteil der Datenspeicherung und -verarbeitung lokal erfolgt, wobei GPU, RAM, CPU und Festplattenspeicher des Computers zur Verarbeitung der Informationen genutzt werden. Eine solche Anwendung ist nur selten auf einen externen Server angewiesen, insbesondere wenn das Spiel offline gespielt wird.
Beide Ansätze haben Vor- und Nachteile: Bei einem Thick Client ist die Instabilität des Netzwerks weniger problematisch als bei einem Thin Client, der sich auf einen Remote-Server verlässt, aber Software-Updates können schwieriger sein, und der Fat Client benötigt mehr Computerressourcen. Bei einem Thin Client können geringere Kosten ein großer Vorteil sein. Bei beiden Client-Arten kann die Bereitstellung persönlicher Daten für die Anwendung eines Drittanbieters ein Problem darstellen.
Webanwendungen
Eine Webanwendung ist eine Software, die auf einem Server läuft, Benutzerinteraktionen verarbeitet und von Fat oder Thin Clients über ein Computernetz kontaktiert wird. Nicht alle Websites gelten als Webanwendungen: Einfache statische Webseiten ohne Interaktivität gelten nicht als Webanwendungen, da der Server keine Anwendung ausführt, um vom Client angeforderte Aktionen zu verarbeiten.
Viele Webanwendungen lassen sich in zwei Gruppen einteilen: Single-Page Applications (SPA) und Multi-Page Applications (MPA). Eine SPA hat nur eine Webseite, auf der der gesamte Datenaustausch und das Laden von Daten erfolgt, ohne dass der Benutzer auf eine andere Webseite innerhalb der Anwendung umgeleitet werden muss. Eine MPA hat im Gegensatz zur SPA mehrere Webseiten. Eine Datenänderung kann entweder dieselbe Webseite aktualisieren, von der die Aktion ausging, oder den Benutzer auf eine andere Webseite umleiten.
Nehmen wir das vorangegangene Beispiel, in dem ein Benutzer seine letzten Kontobewegungen auf der Internetbanking-Website überprüfen möchte. Stellen Sie sich vor, dass eine Transaktion stattfindet, nachdem die Webseite geladen wurde. Wenn es sich bei der Webanwendung der Bank um eine SPA handelt, wird die neue Transaktion automatisch auf derselben Webseite angezeigt, ohne dass der Benutzer auf eine neue Seite umgeleitet wird. Wenn der Benutzer seine Kredite überprüft, werden die neuen Informationen ebenfalls auf derselben Seite angezeigt, ohne dass der Benutzer auf eine neue Webseite umgeleitet werden muss. Die Änderung der Seite ohne Umleitung des Benutzers sorgt für eine flüssige Navigation.
Bei einer MPA muss der Server, sobald der Nutzer die Seite zu den Krediten anfordert, den Nutzer an einen neuen Ort, d.h. eine andere Webseite, weiterleiten.
Ein bekanntes Beispiel für eine SPA ist Google Mail (Gmail), das den Benutzer nicht auf eine neue Seite umleitet, wenn er z.B. den Spam-Ordner anklickt; die Anwendung aktualisiert lediglich den spezifischen Teil der Anzeige, der alle Spam-Nachrichten enthält, und bleibt auf derselben Webseite.
Eine berühmte MPA ist der E-Commerce-Riese Amazon.com, bei dem jeder Artikel auf einer eigenen Webseite zu finden ist.
Ein Vorteil einer MPA gegenüber einer SPA besteht darin, dass Webanalysen viel einfacher zu erfassen und zu messen sind, was für die Optimierung von Internet-Suchergebnissen überaus wichtig ist.
Normalerweise umfasst eine Webanwendung zwei Teile: Frontend und Backend. Das Frontend ist die Ansichtsschicht, in der Benutzer mit einem Browser interagieren und die Seitenelemente durch Klicken, Auswählen oder Eingaben nutzen. Hier werden die Daten vom Server empfangen, formatiert und dem Benutzer über den Browser angezeigt.
Das Backend ist meist der umfangreichere Teil einer Webanwendung. Es umfasst die Geschäftslogik, die Kommunikationshandler, den Großteil der Datenverarbeitung und die Datenspeicherung. Die Datenspeicherung erfolgt über ein separates Datenbankmanagementsystem, das mit dem Backend verbunden ist.
Frontend und Backend kommunizieren miteinander: Datenanfragen werden vom Frontend an das Backend weitergeleitet, und die vom Backend zurückgegebenen Daten werden vom Frontend empfangen, formatiert und dem Benutzer angezeigt.
In unserem einfachen Beispiel der Abfrage der letzten Transaktion auf dem Bankkonto eines Benutzers wird die Aktion vom Frontend der Anwendung interpretiert, das im Browser auf dem Desktop des Benutzers läuft. Diese Anfrage wird dann über das Internet an das Backend der Anwendung gesendet, das prüft, ob der Benutzer die Aktion ausführen darf, die Daten abruft und die Liste der Transaktionen an das im Browser geladene Frontend zurückschickt. Der Browser formatiert dann die Daten und zeigt sie dem Benutzer an.
Application Programming Interface (API)
Software ist nutzlos, wenn sie nicht mit internen und externen Komponenten kommuniziert. Wie also kann der Client mit der Webanwendung kommunizieren? Wie kann das Frontend Daten an das Backend senden?
Softwareanwendungen kommunizieren miteinander über ein Application Programming Interface (API), also eine Programmierschnittstelle, die über grundlegende Protokolle der Internetkommunikation läuft. Protokolle sind Standards und Regeln, die sicherstellen, dass zwei oder mehr Anwendungen Befehle und Daten austauschen.
Der Hauptvorteil einer API besteht darin, dass sie die verschiedenen Teile der Anwendung entkoppelt und es ihnen ermöglicht, bei der Verarbeitung von Daten zusammenzuarbeiten. APIs zentralisieren auch den Datenfluss in vordefinierten Kanälen und wirken wie ein Gateway, das sicherstellt, dass jeder den gleichen Ein- und Ausgang nutzt. APIs sind für die Funktionalität von Webanwendungen von entscheidender Bedeutung, da sie die Interaktion mit dem Benutzer, die Bereitstellung verarbeiteter Informationen, Anfragen zur Datenspeicherung und viele andere Aufgaben ermöglichen. Der Client kann eine API beispielsweise nutzen, um Aktionen anzufordern, die auf dem Server ausgeführt werden sollen.
Zurück zu unserem Banking-Beispiel: Um sich über eine Webanwendung bei einem Konto anzumelden, gibt der Benutzer in der Regel Daten wie Benutzername und Kennwort in bestimmte Textfelder ein und klickt auf die Schaltfläche “Anmelden”. Der Browser erfasst diese Informationen und ruft eine Backend-API auf. Die Webanwendung, die auf dem entfernten Server läuft, empfängt die Benutzerdaten, validiert den Benutzer, überprüft dessen Zugriffsberechtigung und sendet schließlich eine Antwort an den Browser zurück. Damit der Benutzer mit dem Server kommunizieren kann, müssen sowohl der Client als auch der Server Daten hin- und herschicken. Genau das ermöglichen APIs.
Beachten Sie, dass die Webanwendung der Bank keine weiteren sensiblen Informationen preisgibt; sie zeigt dem Benutzer nur die Felder an, die für eine gewünschte Interaktion zulässig und notwendig sind. Der Rest bleibt dem Benutzer verborgen.
Die Kommunikation zwischen APIs kann auf sehr unterschiedlichen Designs und Protokollen basieren. Das Hypertext Transfer Protocol (HTTP) ist das bei weitem am häufigsten verwendete Protokoll in Webanwendungen. Hypertext ist Text mit Links zu anderen Texten, also das Konzept, das den Links in HTML-Webseiten zugrunde liegt. Hyperlinks bilden somit die Grundlage für den Aufbau von Webseiten und deren Darstellung in Browsern.
HTTP wurde für Client-Server-Anwendungen entwickelt, bei denen die Ressourcen von einem Server angefordert und dann über das Netz an den Client gesendet werden, wobei eine vom HTTP-Protokoll vorgegebene Struktur verwendet wird.
Bei einer strukturierten Webanwendung entwerfen die Softwareingenieure die Anwendung in separaten Teilen oder Modulen. Diese Trennung der Zuständigkeiten ermöglicht klar definierte Aufgaben und Verantwortlichkeiten, was zu einer schnelleren Entwicklung und besseren Wartung führt.
Nehmen wir als Beispiel eine Anwendung mit zwei internen Modulen: eines, das die Geschäftslogik implementiert, und ein anderes, das auf die Integration eines Drittanbieters angewiesen ist. Bei diesem Drittanbieter handelt es sich um ein externes Unternehmen, das seine API für einen bestimmten Zweck zur Verfügung stellt, z.B. für die Wettervorhersage. Fällt der Wetterserver aus, ist es unmöglich, Wetterdaten abzurufen; wenn diese Daten für die endgültige Ausgabe aber entscheidend sind, könnte das für den Benutzer vorübergehend ein Problem darstellen, sofern es keine alternative Datenquelle gibt.
Stellen Sie sich nun vor, dass dieser Drittanbieter ersetzt wird und der neue Anbieter dieselbe API auf andere Weise handhabt. Die Trennung der Module bedeutet, dass die Entwickler nur ein Modul aktualisieren müssen. Die Geschäftslogik im anderen Modul muss überhaupt nicht oder nur minimal angepasst werden.
Die Notwendigkeit klarer Prozessstrukturen wirkt sich auch auf das Design der APIs aus, um deren Nutzung zu erleichtern. Das Konzept des Representational State Transfer (REST) beschreibt eine Architektur mit einer Reihe von Richtlinien zur Gestaltung und Implementierung des Zugriffs auf die Daten in einer Anwendung.
Es gibt sechs REST-Prinzipien, von denen wir der Einfachheit halber nur drei erläutern, die für diese Lektion am wichtigsten sind.
- Client-Server-Entkopplung
-
Der Client sollte nur den Ressourcen-URI kennen, über den die Kommunikation mit dem Server erfolgt. Dieses Prinzip ermöglicht eine größere Flexibilität. Wenn beispielsweise die Backend-Seite der Anwendung überlastet ist oder eine größere Änderung in der Architektur einer Backend-Datenbank vorgenommen wird, muss nicht auch das Frontend aktualisiert werden. Es sendet einfach weiterhin dieselben HTTP-Anfragen an das Backend.
- Zustandslosigkeit (Statelessness)
-
Jede neue Anfrage ist unabhängig von den vorhergehenden. Es ist kein Zufall, dass das HTTP-Protokoll für Anwendungen, die den REST-Prinzipien folgen, weit verbreitet ist, da HTTP keine Kenntnis von früheren HTTP-Anfragen hat; für jede neue Anfrage müssen alle notwendigen Informationen gesendet werden, um die Anfrage korrekt zu verarbeiten. Eine Webanwendung, die dieses Prinzip umsetzt, weiß beispielsweise nicht, ob der Client angemeldet (authentifiziert) ist. Daher muss der Client für jede HTTP-Anfrage ein Authentifizierungstoken senden. Der Server kann anhand dieses Tokens überprüfen, ob die Anfrage blockiert oder verarbeitet werden soll.
Einer der Hauptvorteile dieses Prinzips ist die einfachere Skalierung, da der Server Millionen von Anfragen verarbeiten kann, ohne die Benutzerdetails zu überprüfen.
- Mehrschichtige Architektur
-
Die Anwendung besteht aus mehreren Schichten, wobei jede Schicht ihre eigene Logik und ihren eigenen Zweck haben kann, z.B. Sicherheit oder Datenerfassung. Der Client weiß möglicherweise nie, wie viele Schichten es gibt oder ob er direkt mit einer bestimmten Schicht innerhalb der Anwendung kommuniziert.
APIs, die den REST-Prinzipien folgen, werden als RESTful bezeichnet, und im modernen Web folgen viele Webanwendungen dem REST-Design. Obwohl eine RESTful-API diese Grundsätze nicht mit Hilfe des HTTP-Protokolls umsetzen muss, wird es aufgrund seiner Robustheit, Einfachheit und Allgegenwärtigkeit im World Wide Web fast durchgängig im REST-Modell genutzt.
Architekturtypen
Es gibt Dutzende von Architekturstilen und -standards, die die Strukturen von Webanwendungen organisieren. Wie fast immer in der Computerwelt gibt es keinen “Gewinner”, sondern eine Reihe von Vor- und Nachteilen für jedes Modell. Ein wichtiges Paradigma ist die so genannte Microservice-Architektur, die als Alternative zur älteren monolithischen Architektur entstanden ist.
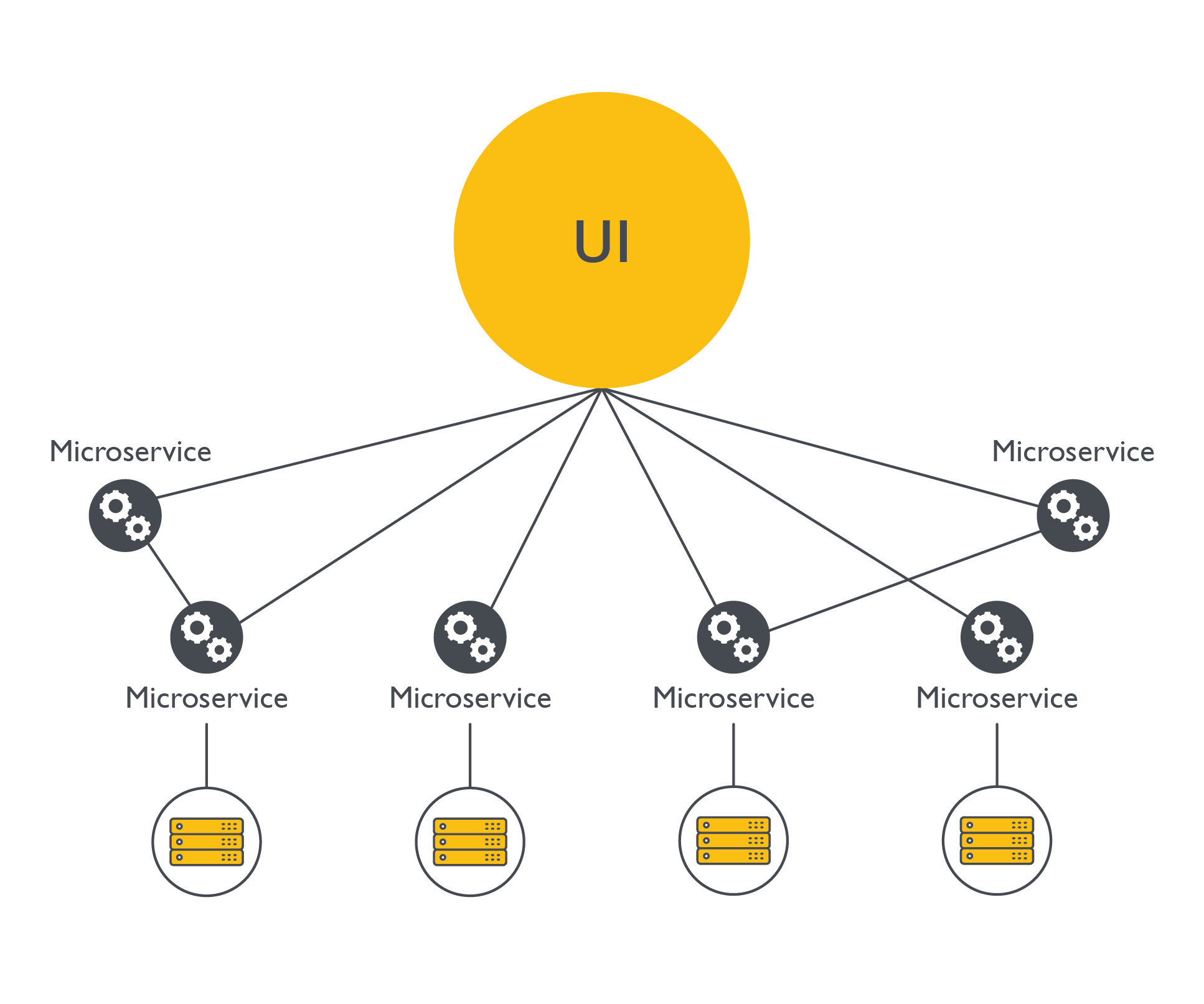
Die Microservice-Architektur ist ein Softwaremodell, das aus mehreren voneinander abhängigen Services besteht, die zusammen die eigentliche Anwendung bilden. Diese Architektur zielt darauf ab, die Codebasis zu dezentralisieren: Mehrere Software-Schichten werden zur besseren Wartung in mehrere kleinere Anwendungen aufgeteilt (Microservice-Architektur).
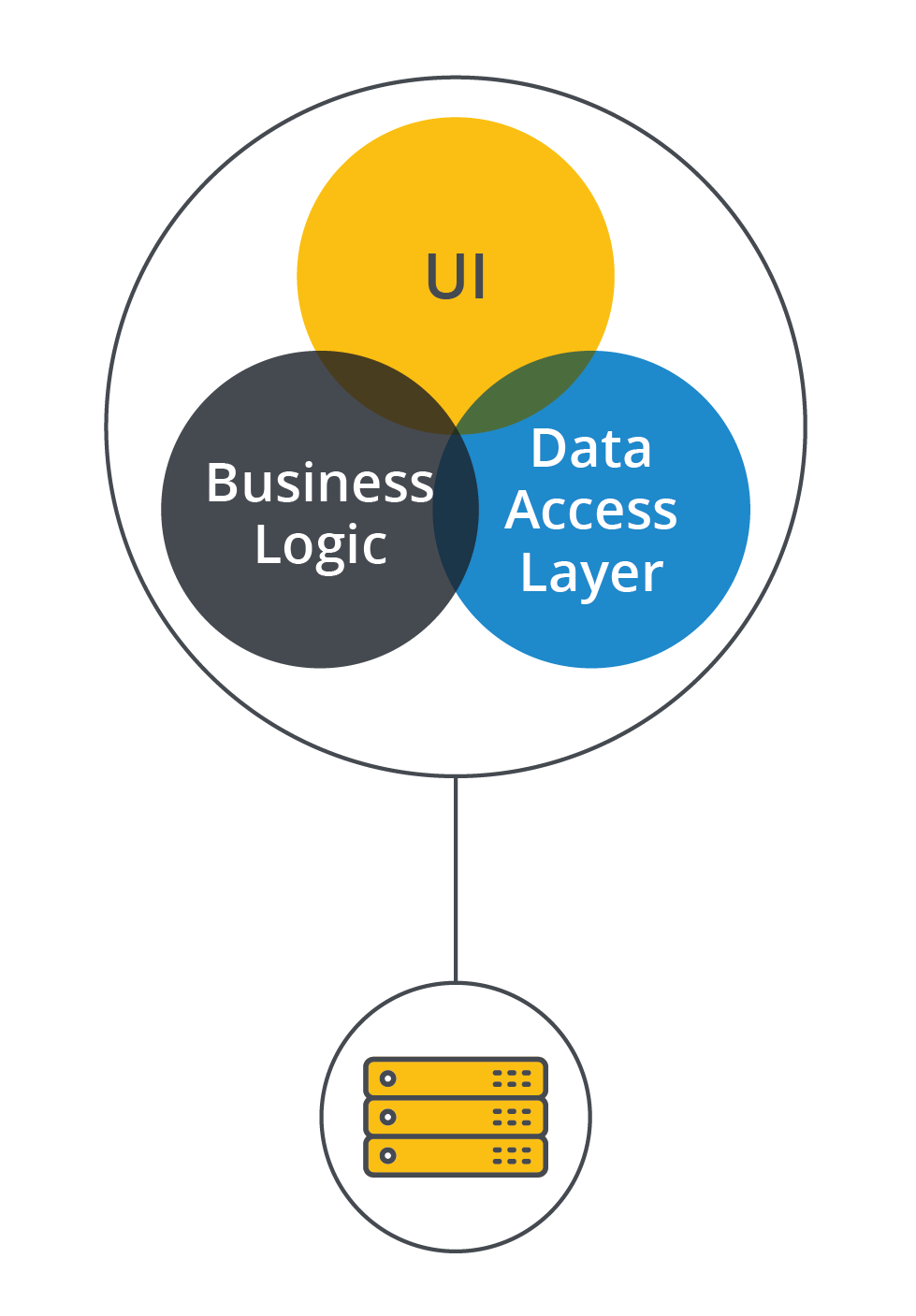
Im Gegensatz dazu umfasst eine monolithische Architektur alle Dienste und Ressourcen der Anwendung in einer einzigen Anwendung (Monolithische Architektur).
Die Abbildungen zeigen, dass das Microservice-Modell dezentralisiert ist und die Anwendung auf mehreren Diensten beruht, von denen jeder seine eigene Datenbank, Codebasis und sogar Serverressourcen hat. Wie der Name schon sagt, sollte jeder Microservice kleiner sein als sein monolithisches Gegenstück, das die Verantwortung für alle Dienste übernimmt.
Die monolithische Anwendung kapselt alle Ressourcen in einer einzigen Einheit. Die gesamte Geschäftslogik, die Daten und die Codebasis sind in einem großen Block zentralisiert, der auch als “Monolith” bezeichnet wird.
Nutzer bemerken kaum, ob eine Webanwendung als monolithisches oder als Microservice-Modell läuft; die Wahl sollte transparent sein. Unsere Bankanwendung könnte beispielsweise ein Monolith sein, bei dem sich die gesamte Geschäftslogik in Bezug auf Zahlungen, Transaktionen, Kredite usw. in derselben Codebasis befindet, die auf einem oder mehreren Servern läuft. Wenn die Bankanwendung hingegen im Microservice-Stil läuft, hat sie wahrscheinlich einen Microservice, der sich mit der Verarbeitung von Zahlungen befasst, und einen weiteren Microservice, der nur für die Vergabe von Krediten zuständig ist. Der letztgenannte Microservice ruft einen weiteren Microservice auf, um die Wahrscheinlichkeit zu analysieren, mit der der Antragsteller mit der Zahlung in Verzug gerät. Die Anwendung könnte aus Tausenden kleinerer Services bestehen.
Der monolithische Ansatz erfordert einen höheren Wartungsaufwand, wenn die Anwendung größer wird, insbesondere wenn mehrere Teams in derselben Codebasis programmieren. Angesichts der zentralisierten Softwareressourcen ist es sehr wahrscheinlich, dass ein Team etwas ändert, das den Teil der Anwendung eines anderen Teams beschädigt. Dies kann für größere Teams zu einem echten Problem werden, insbesondere wenn es eine große Anzahl von Teams gibt.
Microservices sind in dieser Hinsicht deutlich flexibler, da jeder Dienst von nur einem Team verwaltet wird. Ein Team kann natürlich mehr als einen Dienst verwalten. Die Codeänderungen sind leicht durchzuführen und konkurrierende Ressourcen sind kein echtes Problem. Da jeder Dienst mit anderen verbunden ist, kann sich jeder Fehler negativ auf die gesamte Anwendung auswirken. Da außerdem mehrere Datenbankinstanzen, Server und externe APIs miteinander kommunizieren, ist die Ausfallsicherheit der gesamten Anwendung nur so gut wie ihr schwächster Microservice.
Ein Vorteil des monolithischen Ansatzes ist die zentrale Datenquelle, die die Vermeidung von Datenduplizierung erleichtert. Der Ansatz reduziert auch den Verbrauch von Cloud-Ressourcen, da ein größerer Server weniger Computerressourcen benötigt als mehrere dezentrale Server. Eine Microservice-Anwendung von etwa gleicher Größe belastet die Cloud stärker.
Geführte Übungen
-
Was sind die Hauptunterschiede zwischen einem Fat und einem Thin Client?
-
Ist die Annahme richtig, dass jede Website eine Webanwendung ist?
-
Was ist das REST-Modell?
-
Was ist das bevorzugte Modell für die Entwicklung großer, moderner Webanwendungen mit mehreren Entwicklungsteams? Warum?
-
Welches ist das am häufigsten verwendete Protokoll für den Datenaustausch zwischen Webanwendungen?
-
Nennen Sie zwei Nachteile von Multi-Page Anwendungen gegenüber Single-Page Anwendungen.
-
Beschreiben Sie einen Vorteil eines monolithischen Systems gegenüber einem Microservice-System und einen Vorteil, den das Microservice-System gegenüber einem monolithischen System hat.
Offene Übungen
-
Im Jahr 2021 landet der NASA Perseverance Rover auf dem Mars und soll unter anderem herausfinden, ob es jemals Leben auf dem Mars gab. Obwohl der Rover hier auf der Erde aus der Ferne gesteuert werden könnte, kann er sich in den meisten Situationen auch selbst steuern. Warum ist es eine gute Idee, einen solchen Rover als Fat Client zu entwerfen?
-
Stellen Sie sich ein modernes, selbstfahrendes Auto vor, das eine Verbindung zu einem externen Server herstellt, um Daten auszutauschen. Sollte es ein Fat oder ein Thin Client sein?
Zusammenfassung
In dieser Lektion wurden die Kernkonzepte der Softwarearchitektur für Webanwendungen erläutert. Es wurde erklärt, wie diese üblicherweise strukturiert und organisiert sind und worin die Hauptunterschiede zwischen monolithischen und Microservice-Modellen bestehen. Wir haben die Konzepte von Servern und Clients sowie die Grundlagen der Kommunikation von Webanwendungen zwischen Clients und anderen Softwareprogrammen behandelt.
Antworten zu den geführten Übungen
-
Was sind die Hauptunterschiede zwischen einem Fat und einem Thin Client?
Ein Fat Client benötigt keine ständige Verbindung zu einem entfernten Server, der wichtige Informationen an den laufenden Client zurückgibt. Der Thin Client ist in hohem Maße auf die von einer externen Quelle verarbeiteten Informationen angewiesen. Ein weiterer Unterschied besteht darin, dass ein Fat Client für den Großteil der Datenverarbeitung verantwortlich ist und daher mehr Rechenressourcen benötigt als sein Thin Pendant.
-
Ist die Annahme richtig, dass jede Website eine Webanwendung ist?
Es gibt Websites, die keine Softwareanwendungen sind. Eine Webanwendung interagiert mit dem Benutzer, der Daten eingeben und Webfunktionen in Echtzeit nutzen kann. Einfache Websites, wie z.B. Werbung für eine Veranstaltung, die wie ein Webbanner funktioniert, sind keine Webanwendungen. Diese nicht interaktiven Websites sind einfacher zu pflegen und erfordern nur geringe Rechenressourcen für das Hosting und die Bereitstellung der Webseiten. Eine Webanwendung erfordert viel mehr Rechenressourcen, robustere Server und Funktionen für den Umgang mit Benutzern, wie z.B. eingeschränkten Zugang und permanente Datenspeicherung.
-
Was ist das REST-Modell?
Das REST-Modell ist ein Software-Architekturmodell, das Anwendungen einen Entwicklungsleitfaden für bessere Benutzerfreundlichkeit, Klarheit und Wartungsfreundlichkeit bietet. Eines der in den REST-Leitlinien dargelegten Prinzipien ist die Schichtenarchitektur, die in erster Linie dem Zusammenhalt und der Verringerung von Abhängigkeiten der verschiedenen internen Komponenten der APIs dient.
-
Was ist das bevorzugte Modell für die Entwicklung großer, moderner Webanwendungen mit mehreren Entwicklungsteams? Warum?
Das Microservice-Softwaremodell bietet einen flexiblen Rahmen, in dem Teams an derselben Softwareanwendung zusammenarbeiten, was die Gleichzeitigkeit für zwei oder mehr Teams, die eine große Webanwendung pflegen, erleichtert. Da das Framework dezentralisiert ist, kann jedes Team einen bestimmten Geschäftsbereich aktualisieren, ohne andere Komponenten aktualisieren zu müssen-
-
Welches ist das am häufigsten verwendete Protokoll für den Datenaustausch zwischen Webanwendungen?
HTTP ist das am häufigsten verwendete Protokoll für den Austausch von Daten und Befehlen zwischen Servern und Clients.
-
Nennen Sie zwei Nachteile von Multi-Page Anwendungen gegenüber Single-Page Anwendungen.
Bei einer Multi-Page Anwendung werden alle Elemente der Webseite neu geladen, sobald der Benutzer bestimmte Aktionen auslöst, anstatt nur die geänderten Elemente zu aktualisieren. Darunter leidet die Performance. Ein weiterer Nachteil einer MPA ist die trägere Benutzerinteraktivität, da jedes Laden einer Seite die Benutzerfreundlichkeit mindert. Im Gegensatz dazu können visuelle Übergänge bei einer SPA glatter sein.
-
Beschreiben Sie einen Vorteil eines monolithischen Systems gegenüber einem Microservice-System und einen Vorteil, den das Microservice-System gegenüber einem monolithischen System hat.
Ein monolithisches System kann die Datenverwaltung erleichtern, da sich die Daten in einer großen Datenbank befinden, anstatt in mehreren Datenbanken verstreut zu sein. Eine Microservice-Anwendung hingegen kann die Codeentwicklung und -wartung verbessern: mehrere Teams können an verschiedenen Geschäftslogiken arbeiten, ohne den Fortschritt anderer Teams zu blockieren.
Antworten zu den offenen Übungen
-
Im Jahr 2021 landet der NASA Perseverance Rover auf dem Mars und soll unter anderem herausfinden, ob es jemals Leben auf dem Mars gab. Obwohl der Rover hier auf der Erde aus der Ferne gesteuert werden könnte, kann er sich in den meisten Situationen auch selbst steuern. Warum ist es eine gute Idee, einen solchen Rover als Fat Client zu entwerfen?
Die Zeit, die ein Kommunikationssignal braucht, um von der Erde gesendet und auf dem Mars empfangen zu werden, kann je nach Position der beiden Planeten variieren, aber bis zu zwanzig Minuten betragen. Daher ist es unmöglich, einen entfernten Rover in Bewegung zu kontrollieren, insbesondere in unerwarteten Situationen. Im Idealfall sollte sich der Rover in den meisten Situationen selbst steuern. Dies wird durch Training mit künstlicher Intelligenz (KI) erreicht (maschinelles Lernen), so dass der Rover unabhängiger von manuellen Befehlen wird. Um weniger auf Signale aus der Ferne angewiesen zu sein, ist der Rover so konzipiert, dass er über eigene Ressourcen verfügt und den Großteil der Rechenprozesse lokal ausführt, was der Definition eines Fat Client entspricht.
-
Stellen Sie sich ein modernes, selbstfahrendes Auto vor, das eine Verbindung zu einem externen Server herstellt, um Daten auszutauschen. Sollte es ein Fat oder ein Thin Client sein?
Ein autonomes Fahrzeug könnte die aufwendige Datenverarbeitung an einen externen und zuverlässigen Server delegieren, aber dieser wäre anfällig für Offline-Perioden, wenn kritische Datenverarbeitung erforderlich ist. Daher ist es zwingend erforderlich, dass das autonome Fahrzeug den Großteil der Aufgaben verarbeitet — und das erfordert, dass es ein Fat Client mit mehrfacher Redundanz ist.